4 Levels of AI safety regulation
As AI capabilities increase, the risks these systems pose to humanity increase as well. Many scientists have already warned about the risk of human extinction .
In this article, we’ll look at our 4-levels framework for thinking about how AI safety can be regulated.
AI pipeline as a framework for safety governance
The AI creation pipeline consists of various steps, each of which can be regulated in different ways. This pipeline consists of:
- Hardware & algorithms, which are used for training AI models
- Training runs, where the hardware and algorithms are used to create a model
- Deployment, where the trained model is shared with the public
- Usage, where the deployed model is utilized by individuals and companies
The later in the pipeline we regulate, the higher the risks we face. If we want a high level of safety, we’ll need to regulate earlier in the pipeline. That’s why when we climb up the 4 levels of AI regulation, we walk back the AI creation pipeline.
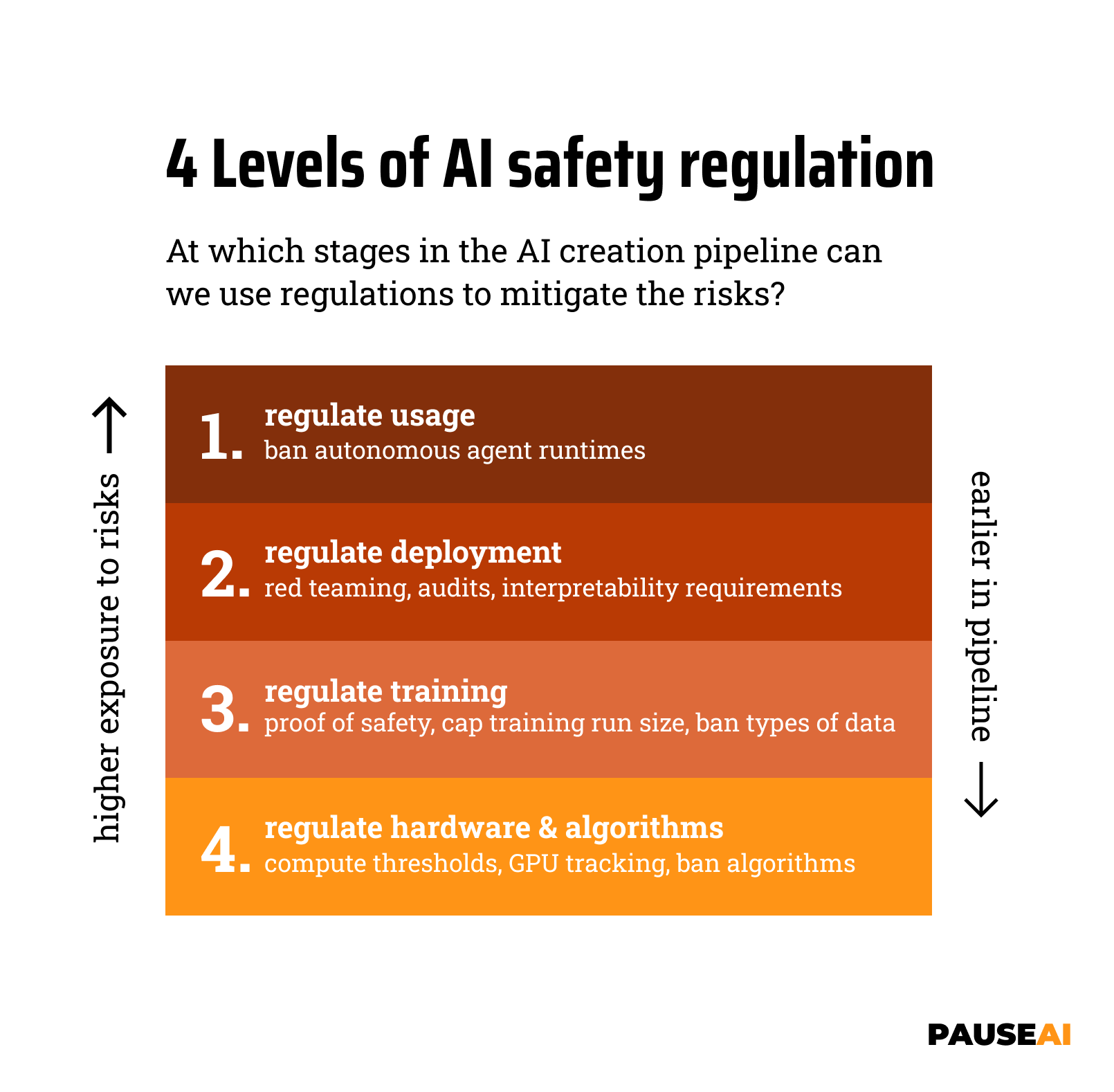
Level 1: Regulate usage
Examples:
- Ban autonomous agent runtimes (like AutoGPT)
- Ban dangerous instructions
These measures are aimed to prevent users from doing dangerous or harmful actions with AI models. At this level, the responsibility lies with the users of the models, not the creators. We’re depending on all the (potentially millions) of users to abide by the regulations. This only provides a very low level of protection against AI dangers.
Level 2: Regulate deployment
Examples:
- Red-teaming requirements. This means that before an AI model is deployed, it is tested by a red team to see if it can be hacked (jailbroken) or abused.
- Disallow deployment and open-sourcing of models with dangerous capabilities .
When regulating deployments, we are preventing dangerous models from being available. This means the responsibility lies with the creators of the models. This is a safer situation than level 1, because we’re now depending on a much smaller group of people to act responsibly.
However, we’re still allowing dangerous training runs to happen, so accidents at AI labs (including the leaks of dangerous AI models, or rogue AI being created) can still happen.
Level 3: Regulate training runs
Examples:
- Require proof of safety before granting permission to train a certain model. This may include formal proof of alignment. This post details some of the current safety problems .
- Setting a scale ceiling for training new models (e.g. a maximum count of flops used). This could also include the process of fine-tuning.
- Require a license to train AI models (above a certain size / with certain capabilities).
- Ban training on dangerous types of data. Some types of training data can lead to dangerous capabilities , such as hacking or the creation of bioweapons. We could ban training on data that contains this type of knowledge.
- Ban training on copyrighted data. This does not directly target unsafe data, but it does limit the amount of data that can be used, which means it buys us time to figure out to build safe AI models.
When we regulate training runs, we prevent dangerous models from being created in the first place. This will prevent accidents at AI labs that comply with the regulations.
However, we’re still allowing the distribution of hardware and algorithms that can be used for training dangerous models, so we’re still relying on the creators of these models to act responsibly.
Level 4: Regulate hardware & algorithms
Examples:
- Limit distribution of training hardware. Specialized hardware for training AI models is rapidly becoming the most important product of chip manufacturers. The supply chain for this hardware is very centralized, and the hardware is very expensive. This means that it’s relatively easy to regulate the distribution of this hardware.
- Disallow the publication of novel training architectures. New AI training architectures can lead to dramatic increases in capabilities. The Transformer model, for example, enabled virtually all recent progress in AI. We could limit the publication of such architectures to prevent sudden capability jumps.
When we also regulate hardware and algorithms, we’re making it not just illegal, but also very difficult to train dangerous models. This gives us the best protection against the risks from AI.
Limitations
Note that this framework is not perfect, and not all possible types of AI regulation neatly fit in one of the mentioned levels. For example, legal liability for model creators can be classified as a Level 1 “usage” type of regulation as it is enforced post-deployment, but it could also be classified as a Level 2 or 3 type of regulation as it can help creators reconsider if a certain model should be deployed or trained in the first place.
Conclusions
In this article, we’ve looked at our 4-levels framework for thinking about how AI safety can be regulated. Using this model, we can more easily reason about the effectiveness of AI regulation at different steps in the AI creation pipeline. We can also see that the first two levels do not offer much protection against the (existential) risks from AI. Preventing dangerous training runs and regulating hardware and algorithms are far more reliable ways to ensure safety.